Pyramidal Attention for Saliency Detection
- Abstract
- Additional Comments
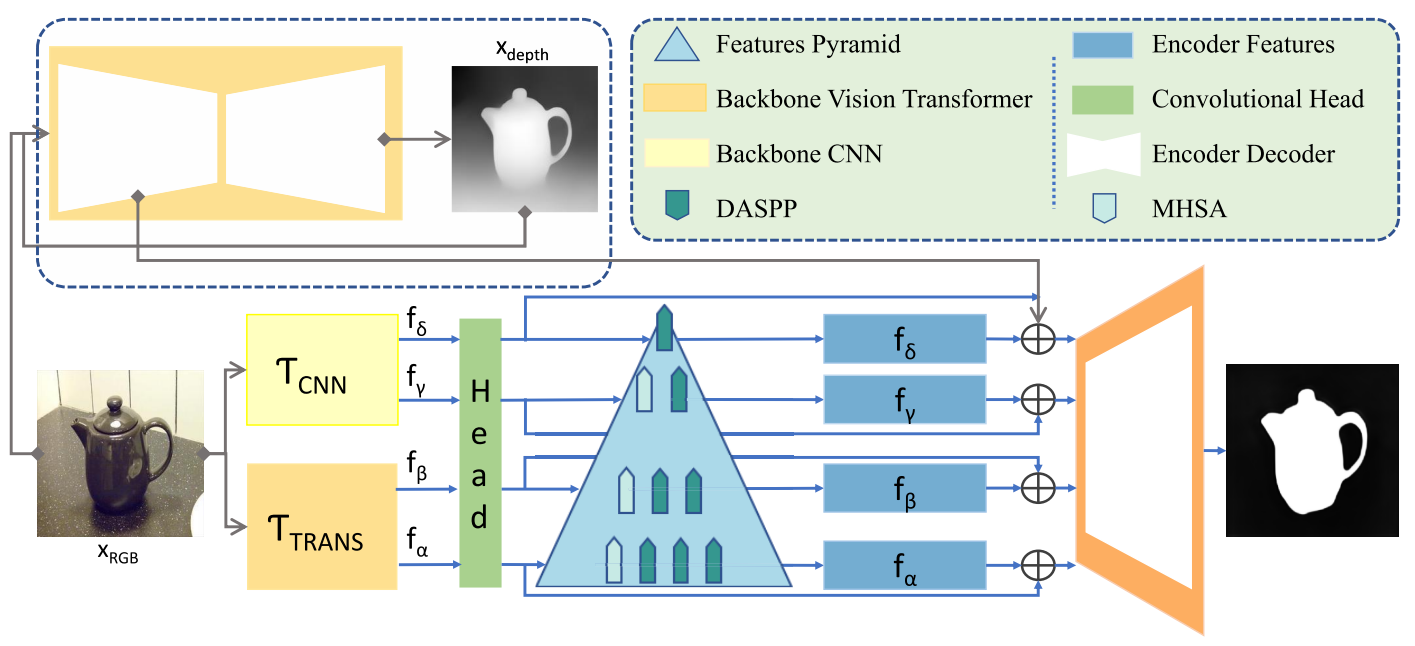
Salient object detection (SOD) extracts meaningful contents from an input image. RGB-based SOD methods lack complementary depth clues, limiting performance in complex scenarios. While RGB-D models utilize depth information, their reliance on depth data during testing restricts practical applicability. This paper proposes a method that uses only RGB images, estimates depth from RGB, and leverages intermediate depth features. A pyramidal attention structure is introduced to extract multi-level convolutional-transformer features, enhancing representations at each stage. The backbone transformer captures global receptive fields, and a residual convolutional attention decoder refines predictions for optimal saliency detection. The proposed approach achieves significant performance improvements over numerous state-of-the-art SOD methods across multiple RGB and RGB-D datasets. This work presents a new perspective on RGB-D SOD without requiring depth data during training or testing, effectively incorporating depth cues to improve RGB-based saliency detection.