Dual Deep Learning Network for Abnormal Action Detection
- Abstract
- Additional Comments
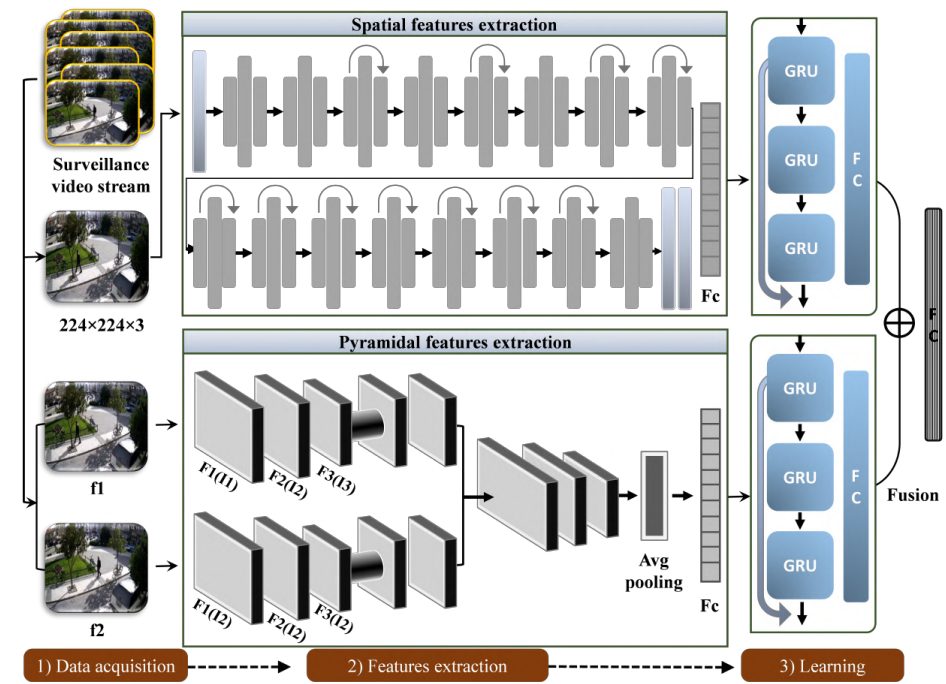
Neural networks have demonstrated remarkable effectiveness in solving distinct real-world vision problems pertaining to activity recognition and violence detection in surveillance scenarios. The broad reliance on practicing a single network for spatial and motion information collection has made them less effective for long-term dependency analysis in video snippets. Our work solves this issue through a multi-network fusion strategy suitable for real-world surveillance. Initially, the spatial information is accessed from a compound coefficient strategy inspired by a robust convolutional neural network (ConvNet). Next, the pyramidal convolutional features from two consecutive frames are obtained through LiteFlowNet. The output from both the networks (ConvNet and LiteFlowNet) is separately passed into a deep-gated recurrent unit (GRU) assembled with skip connections. The outputs obtained from each GRU are fused and further propagated to the dense layer for final decision. The results on the datasets and ablation study confirm our method’s efficiency, outperforming the state-of-the-art methods.