Action understanding in low-light and pitch-dark conditions: A comprehensive survey
- Abstract
- Additional Comments
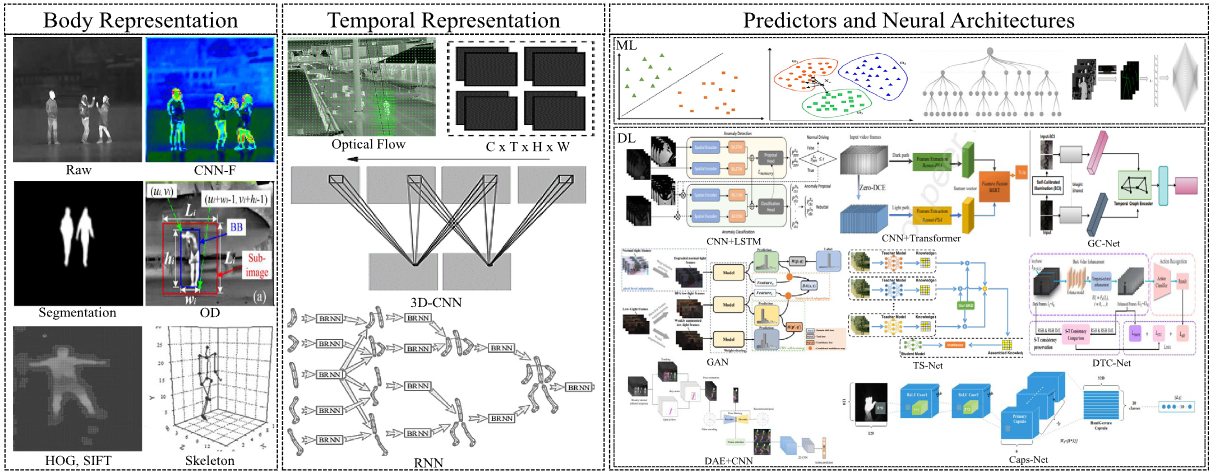
Action understanding in low-light and dark environments (AULLD) is a critical and technically demanding challenge at the intersection of computer vision and engineering applications. This task focuses on interpreting human actions using motion cues under visually constrained conditions, such as poor illumination or complete darkness. Since 2010, machine learning and, more notably, deep learning have significantly advanced AULLD by enabling systems to extract and learn discriminative features from complex, low-visibility data. These techniques have resulted in state-of-the-art solutions, with recent methods achieving accuracies on various benchmark datasets of up to 97.10%, and a 73.20% top-1 accuracy on an infrared dataset. These solutions have had applications across domains such as healthcare monitoring, surveillance and security, human–computer interaction, and social computing. In this survey, we provide the first comprehensive overview of the progress of the research and topical developments in AULLD. We cover a broad range of elements, including the datasets, evaluation protocols, methods, challenges, and emerging research directions. To organize and evaluate the literature in a structured, integrated way, we introduce a novel taxonomic framework, grounded in four core dimensions: body representation, temporal representation, feature representation, and neural architectures. Employing this taxonomy, we perform an analysis of AULLD approaches, exploring their methodological foundations, system design considerations, performance outcomes, and inherent trade-offs. The survey concludes with an in-depth discussion of the existing challenges confronting AULLD, highlighting several promising research directions that hold potential for advancing the field and setting the stage for future innovations and improvements in AULLD.