Quality over quantity: a data-centric survey of annotation errors in object detection datasets
- Abstract
- Additional Comments
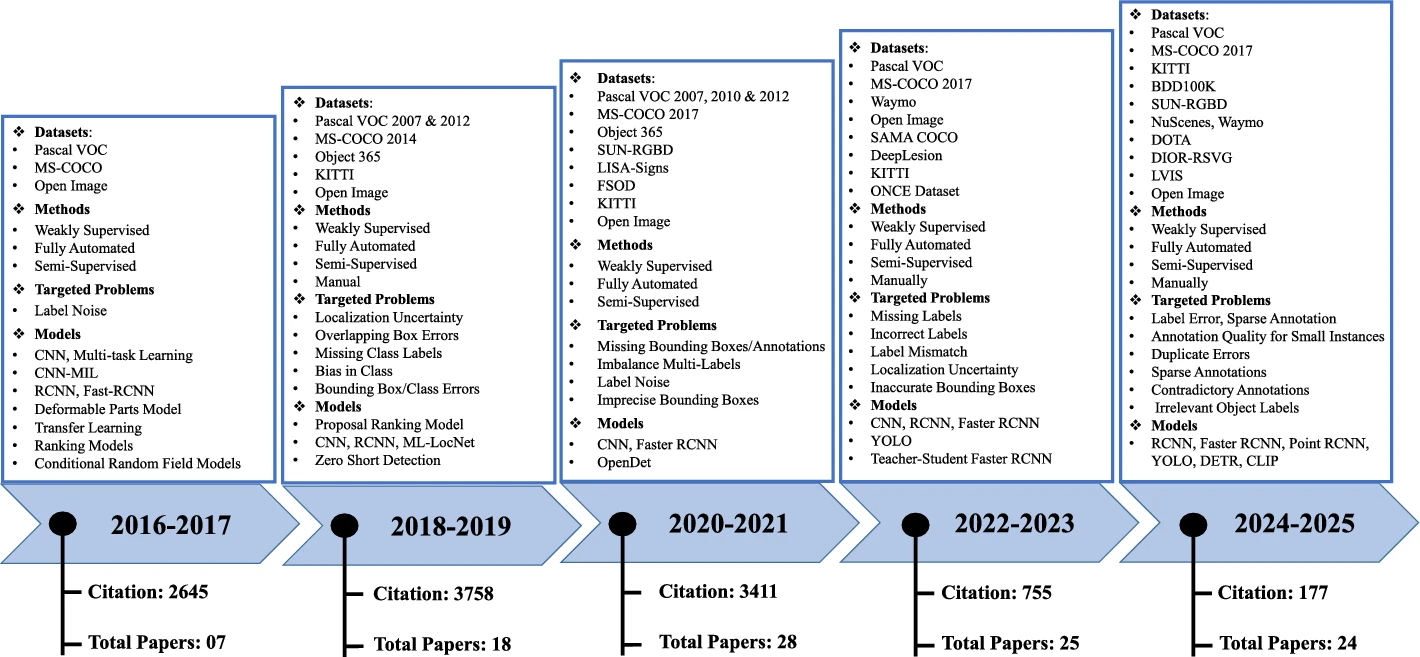
In recent years, object detection has become a cornerstone of many computer vision applications, relying heavily on the availability of high-quality annotated datasets. However, even widely used benchmarks often suffer from annotation issues such as inaccurate bounding boxes, misclassified objects, and missing labels. These annotation errors, especially localization errors, can greatly affect the training and evaluation of detection models. In this survey, we provide a data-centric and comprehensive review of existing methods for identifying and analyzing errors in object detection datasets. We examine the main components of error detection workflows, including annotation error taxonomies and model-agnostic detection techniques. In addition, we develop a standardized categorization of annotation error types specific to object detection, providing a foundation for consistent analysis and comparison across studies. We also perform manual inspections of selected benchmark datasets to observe and quantify common annotation errors in practice. Moreover, the survey highlights the datasets used for evaluating error detection methods and compares their scope and inherent challenges. Finally, we summarize the types of annotation errors found in existing benchmarks and provide recommendations for future research to enhance dataset quality and reliability in object detection.